Using AI to create self describing PNG files
One of the advantages of working on the community team at Adobe is I get to help solve real world problems for super creative people (inside and outside Adobe). Chatting with my team this week, we had a discussion about how big of a hassle it is managing and searching screenshots. I thought this might be a fun project to tackle over the weekend.
My first thought was to just throw the image and the search at AI and have it give me the results, but that would be slow, and would not work at all if you are searching lots of screenshots. Thinking about it, what I really wanted to do is to embed a little LLM directly into the PNG, and have it tell me about itself when I need the info (things such as content, text, description, etc…).
Thats when I realized I could do that, at least for the content I needed.
Introducing png-meta. It’s a proof-of-concept tool that watches a directory for new PNG files, generates a description using AI, and stores that description—along with other metadata—inside the PNG as JSON.
https://github.com/mikechambers/png-meta
It essentially creates self-describing PNGs that can be useful for search, cataloging and analysis.
For example:
$uv run src/png-meta.py --dir ~/Desktop/Screenshots --scan --watch
scans existing PNGs in the directory and then watches for new ones to be added.
When a new PNG is found, it sends it to AI (in this case OpenAI), has the AI return a description and other information and then writes the data as meta data within the PNG. Data stored includes a description of the content, text extracted from the image, type of image, and apps contained within the image.
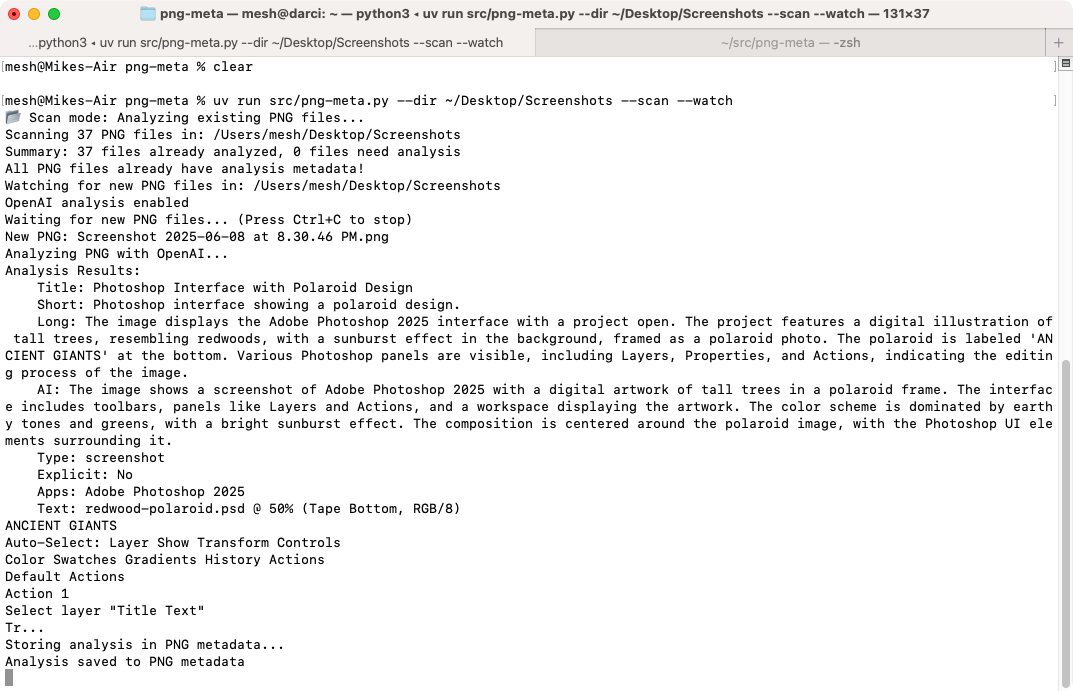
Note, these screenshots include meta data from the project
The project also includes a search script that allows you to run prompts against the PNGs.
$uv run src/png-search.py --dir ~/Desktop/Screenshots/ \
--prompt "show me all the screenshots that contain Adobe Illustrator"
The search tool uses AI on the meta data description to filter the images, which is significantly faster than if it was to scan the images in realtime.
$uv run src/png-search.py --dir ~/Desktop/Screenshots/ \
--prompt "show me all of the screenshots that contain the word python" --paths
#outputs
"/Users/mesh/Desktop/Screenshots/Screenshot 2025-06-08 at 5.22.00 PM.png"
"/Users/mesh/Desktop/Screenshots/Screenshot 2025-06-08 at 5.20.47 PM.png"
To open the found files in Preview on mac:
$uv run src/png-search.py --dir ~/Desktop/Screenshots/ \
--prompt "show me all the screenshots that show Adobe Illustrator" \
--paths | xargs open
You can also access the meta data directly with tools such as exiftool to view the content. For example:
exiftool "Screenshot 2025-06-08 at 5.20.47 PM.png" | grep Png-meta-data
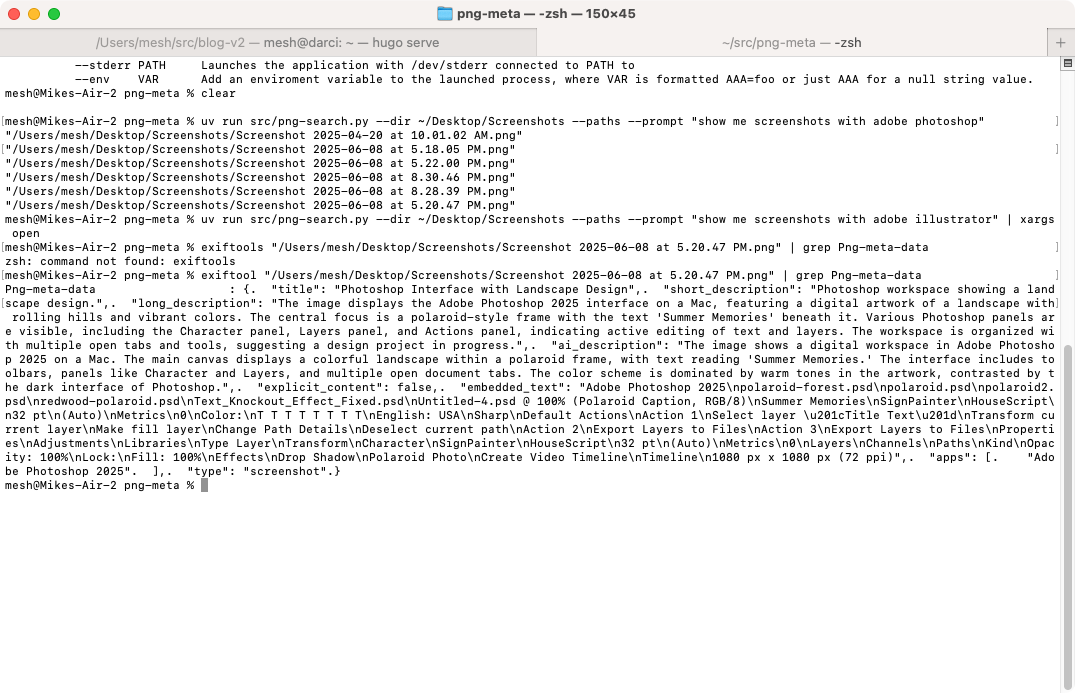
The data is stored as a JSON object within the PNG file in a tag named “png-meta-data”.
| Field | Type | Description |
|---|---|---|
| title | string | Concise, descriptive title for the image (3-8 words) |
| short_description | string | Brief one-sentence description (under 100 characters) |
| long_description | string | Detailed description of what’s shown in the image (2-4 sentences) |
| ai_description | string | Technical analysis for AI systems including visual elements, composition, colors, style, etc. (2-3 sentences) |
| explicit_content | boolean | true if image contains adult/explicit content, false otherwise |
| embedded_text | string | All readable text extracted from the image, preserving structure when possible (includes UI elements, buttons, menus, document content, code, etc.) |
| apps | array[string] | List of application names, window titles, or software interfaces visible in the image |
| type | string | Image classification - one of: “screenshot”, “photograph”, or “graphic” |
I think this is particularly interesting as input / source for context for AI. While it would be possible to send an image, by pre-calculating the description for a specific and common use case, you can send much more data and images and get a much faster response.
And because its stored within the PNG, its portable and goes where the PNG goes.
Again, this is just a proof of concept, but as we move into a world where assets that can be used as an input to AI are going to have a premium on those than cannot, essentially pre-caching the description at authoring time might be a useful approach.
The next steps for this would be to standardize on how to store the data and which data is stored. My version is optimized for my use cases (finding screenshots by the Adobe apps that contain), but you can imagine more generic fields, or even more domain specific ones.
It should also be pretty simple to add support for tools like Photoshop to embed the data on export (should be able to do this with a plugin). It should also be possible to create a Mac Spotlight plugin that could index the data.
Finally, it should be possible to add similar support to any file type (such as Photoshop PSDs) to make it easy to scan them or use them as context for AI.



